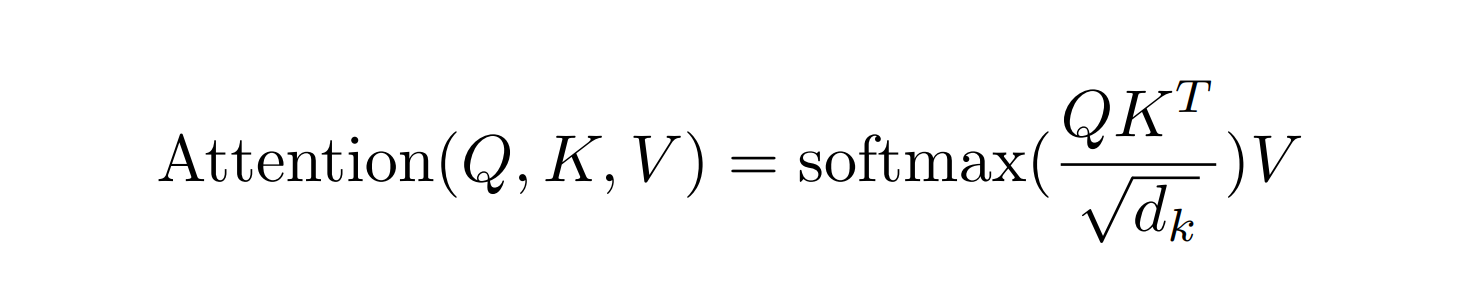In the previous chapter, I introduced the FlashAttention mechanism from a high-level perspective, following an "Explain Like I'm 5" (ELI5) approach. This method resonates with me the most; I always strive to connect challenging concepts to real-life analogies, which I find aids in retention over time.
Next up on our educational menu is the vanilla attention algorithm—a dish we can’t skip if we're aiming to spice it up later. Understand it first, improve it next. There's no way around it.
By now, you've likely skimmed through a plethora of articles about the attention mechanism and watched countless YouTube videos. Indeed, attention is a superstar in the world of AI, with everyone eager to collaborate on a feature with it.
So, I'm also jumping into the spotlight to share my take on this celebrated concept, followed by a shoutout to some resources that have inspired me. I'll stick to our tried-and-tested formula of employing analogies, but I'll also incorporate a more visual approach. Echoing my earlier sentiment (at the risk of sounding like a broken record), the most effective learning happens when we connect new information to our everyday experiences.
Let’s begin!
Although the attention mechanism is an earlier concept (Bahdanau et al., 2014, Luong et al., 2015), the paper “Attention is all you Need” (Vaswani et al., 2017), with its provocative title, gave it the love it deserved. The paper unveiled the transformer architecture, showcasing its prowess in machine translation and unknowingly handing the attention mechanism the keys to the AI kingdom.
Suddenly, this not-so-humble building block of the transformer architecture was catapulted to celebrity status, becoming the go-to solution for nearly everything in Deep Learning. From the intricacies of language to the nuances of images, the rhythms of sound, and even medicine, everything seems to be under its spell (Dosovitskiy et al., 2021, Radford et al., 2021, Jumper et al., 2020).
So, if you need to understand one thing about AI today, you need to understand how the attention mechanism works, why it is so good at what it does, and why scaling it to handle longer sequences is so remarkably challenging.
The Notion of Contextualized Embeddings
By now, you should be as familiar with the term "word embedding" as you are with your right hand (Mikolov et al., 2013). This concept describes the process of turning a word into a multi-dimensional vector that somehow captures its semantics. Now, in the world of Large Language Models (LLMs), we mainly work with tokens, which usually represent pieces of words. However, let’s assume that a token is a whole word for now. This will make our lives much easier.
With this in mind, imagine diving into this embedding space—it's like exploring a bustling city where words live. Picture the word "nice" renting a green apartment in the “adjectives quarter”, hanging out with neighbors who all have that positive vibe. So, other words like "pleasant", "lovely," and "delightful" might drop by for tea. Do you get the point? In this city, words find their tribe, forming cliques based on their semantic secrets.
But wait; we have a problem! Consider this brain teaser: the phrase "Mickey Mouse is an American cartoon character co-created in 1928 by Walt Disney and Ub Iwerks" versus "a computer mouse is a hand-held pointing device that detects two-dimensional motion relative to a surface." To us humans, it's crystal clear that the word "mouse" in the first sentence is about a legendary cartoon character who happens to be, well, a mouse. Meanwhile, in the second sentence, "mouse" refers to that tech gadget we all love to click, drag, and sometimes vigorously shake when the computer freezes.
But for a neural network, the word “mouse” is mapped initially only to a single vector. So, how can our AI deduce the meaning of it in these wildly different sentences? It employs the same detective skills we do: it examines the context, the surrounding words in the sentence.
To pull this off, we need our words to chat amongst themselves. In our example, “Mickey” and “Disney” need to nudge the “mouse” vector towards the “cartoon heroes” neighborhood. Meanwhile, words like “computer” and “device” should give the other “mouse” a push towards the futuristic metropolis of Techland. In other words, we need to calculate the contextualized embedding for the word “mouse” in each case. And that’s what attention does!
The Attention Mechanism
Now that we've gotten to grips with the purpose of the attention mechanism, it's time to dive into how it works its magic. Let's take a detour into the world of online dating for an example that will make everything easier to understand.
Picture an app like Tinder, where you set up a profile showcasing what you bring to the romantic table (your dazzling personality, your unmatched ability to boil eggs, etc.) and outline what you're on the lookout for in a partner. The first step is to gather everything that you have to offer into a multi-dimensional vector known as the Key (K), and what you're looking for into another vector called the Query (Q). The app's job is to play matchmaker, comparing your offerings to everyone else's wish lists, and your wish list to what everyone else is offering. And there you have it; that's essentially the initial step of what the attention mechanism does.
To this end, each word embedding is transformed to a Key vector and a Query vector, using corresponding matrices. These matrices are weights that the model (i.e., the transformer) needs to learn during training. Next, we play a game of matchmaking: comparing each Key vector with every Query vector to see which words should pay attention to which other words. This helps them gather more context and insights about the topic of the document they are part of. And in Deep Learning, when we say “compare”, we usually mean taking the dot product between the two vectors. The higher the score, the stronger the connection. It’s like finding out which words are meant to be best friends based on their compatibility scores. Let’s leave that aside for a second and return to our online dating analogy.
Just as every person has their own unique personality, a blend of innate values (let’s call that the character) and the influence of their environment, words operate in a similar fashion. Their embeddings carry their initial semantic values, their “character”. But when it comes to computing the contextualized embeddings we've been talking about, every word in a document plays a role in shaping the “personality” of the word. However, not every word exerts the same level of influence. It's like pondering the impact of each person we meet during our lifetime: some leave a lasting imprint, while others are just bystanders. The question then becomes: how much does each word affect another word?
With this concept in mind, we roll out the red carpet for another vector, the Value (V) vector—again produced by a matrix that the model has to learn during training. The Value vector, initially, encapsulates the “character” of each word. The question now is, how much does this “character” shape the “personality” of every other word in the document? Fortunately, we've already determined the compatibility score between each word, so, let's use it! The updated value of each word, or its new contextualized embedding, is determined by a weighted sum. This sum considers the values of all the other words in the document, with the weights being the previously computed compatibility scores. That’s it! To link that with our analogy, it’s like people that are compatible with you in some way, have a bigger effect on your personality than mere strangers.
In reality, there's an important step we take with the compatibility score before using it in the weighted sum. We transform it into a probability distribution using softmax. This means that each score is adjusted to fall between 0 and 1, and together, all the scores add up to 1. While this might seem like a mathematical formality, it's a pivotal step. However, for our intuitive understanding of the attention mechanism's inner workings, this detail, though crucial, doesn't alter the big picture we've painted.
Show me the Math
Analogies and simple examples are fantastic for gaining a conceptual understanding of complex topics, breaking them down into digestible chunks. However, to dive deeper into the world of AI, you need to go through some math. Fortunately, the mathematics behind the attention mechanism isn't too difficult to grasp.
If the idea of diving into formulas makes you a bit nervous, don't worry! The key formula we need to analyze is surprisingly approachable. Here it is:
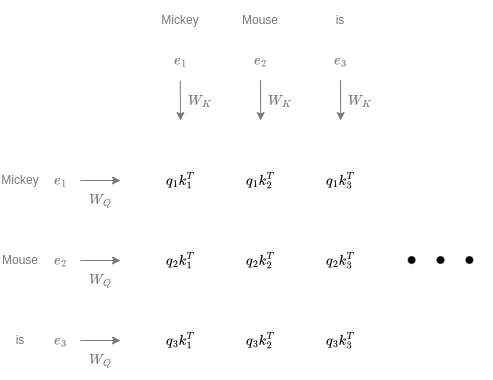
The whole previous section is summarized into one line. That’s the beauty of math! Let's break this down: We're working with three matrices labeled Q, K, and V. These represent the Queries, Keys, and Values for each word, all neatly stacked vertically. The first step in the process is multiplying the Q and K matrices, which results in a square matrix matrix. This matrix isn’t just any grid—it’s a scoreboard that reveals how each word relates with others within our document’s context.
The table above might look like an instance of a Scrabble game, but actually, it's summarizing our discussion in the previous paragraph. First, let’s set up a common dialect: if you see something in lowercase, think “vector”. If it’s in ALL CAPS, that’s a “matrix”. We start by transforming the embeddings of each word into queries and values with their respective matrices. Then, we calculate a square matrix, where each slot holds the compatibility score between words.
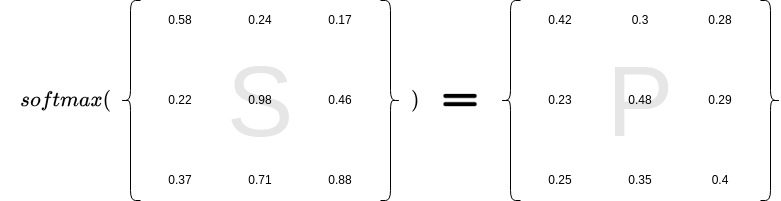
Next up, we perform a softmax operation to transform these compatibility scores into a probability distribution, like we discussed before. The denominator in this operation is there just for stability; it does not offer much to our narrative but ensures everything works smoothly in the background. Let’s set up a running example with real numbers:
In this figure, we're presented with two matrices. The first, matrix S, is an old friend—it's the one packed with compatibility scores for each word in the sentence. Next, we calculate a row-wise softmax transformation. This trick turns our scores into a probability distribution. Now, in each row the numbers stay between 0 and 1 and their total always adds up to 1.
Finally, we multiply the result of the softmax operation with the Values matrix, V, which holds the value of each word, again, stacked vertically. This step produces the weighted sum we’ve been talking about, where each word contributes to the meaning of another, influencing its “personality”. This way, our model distinguishes a real, living, furry mouse from a technological gadget.
If we take a closer look, our running example reveals that the personality of the word in the first row has gone through a bit of a makeover—it now reflects a blend of the values of the other three words (in columns), mixed at proportions of 0.42, 0.30, and 0.28. That’s it! The updated “personality” of each word is represented in each row of the resulting matrix, A.
The last step involves transforming each row of the matrix back into a word embedding. To this end, all we have to do is to multiply this matrix with another one, called the output matrix. This nifty matrix projects each row back into the embedding space, tweaking the dimensions as necessary to fit perfectly. It's like resizing a picture to fit your favorite frame! With this small operation, we’re done!
Conclusion & Next Steps
In this part of the series, we've demystified the attention mechanism with handy real-world analogies and simple visualizations to make the tricky bits stick. Coming up in Part II, we’ll explore the different types of attention, unravel the mysteries of multi-headed attention, and dive hands-first into PyTorch code, implementing the attention block ourselves.
As a bit of 'homework,' why not try crafting your own attention function in PyTorch? With the groundwork we've laid today, you're more than ready to tackle it. See you in the next chapter!
Resources
📚️ Reading form: The Illustrated Transformer (Jay Alammar)
👩💻️ Code: Let's build GPT from scratch, in code, spelled out (Andrei Karpathy)
👀️ Visual approach: Attention in transformers, visually explained (Grant Sanderson)
 |
$5.00
Learning Rate
Thank you for your support! It keeps the doors open and the wheels rolling.
Photo by Rock'n Roll Monkey on Unsplash |